We are excited to announce the preview of Sail, an open-source computation framework with the mission to unify batch processing, stream processing, and compute-intensive (AI) workloads. In today’s data-driven world, organizations of all sizes face a common challenge: efficiently and effectively leveraging vast amounts of complex data from various sources. Sail marks the latest innovation in the solutions to this challenge, and transforms how we handle Big Data in the AI era.
As the first milestone, Sail can now be used as a drop-in replacement for Apache Spark in single-process settings. PySpark users can continue using the DataFrame API and Spark SQL, while enjoying drastically higher performance powered by Sail. Our benchmark results show that Sail offers nearly 4x speed-up, with 94% less hardware cost and zero change to your PySpark code.
The Big Data Challenge in the AI Era
Inadequate data tooling hinders business innovation and growth. The situation becomes more challenging in the AI era, when it is crucial to leverage vast and complex data for the success of your organization. We find a few limitations in existing Big Data solutions, despite their wide adoption and success in the past.
- Library inefficiency. Existing solutions in the Hadoop ecosystem are implemented in JVM programming languages, known for their high resource usage. Columnar file formats are not sufficiently leveraged, leading to performance bottlenecks in modern hardware.
- System fragmentation. Existing solutions focus on either data processing or AI models, but not both. An organization has to own multiple systems, leading to developer inefficiencies and limited insights into their data assets.
- Architecture mismatch for cloud-native environments. Pre-cloud technologies are not designed for the decoupled storage and compute setting in cloud-native environments. It is also not part of the design to leverage cloud services for metadata storage, monitoring, and auto-scaling. This results in increased operational complexity and infrastructure cost.
- The “last mile” data problem for AI. Integrating AI with existing data processing systems is expensive and technically challenging, especially for smaller organizations. This is mostly due to limited language interoperability and inefficient data exchange among systems. Organizations with scarce engineering resources are not able to leverage their proprietary data for AI model training and inference, resulting in missed business opportunities.
The Need for a Unified Solution
We believe that the only way to tackle the Big Data challenge in the AI era is to rethink about the landscape holistically. We envision a unified solution with the following capabilities.
- End-to-end. The solution must be capable of operating on the entire lifecycle of data applications, from data ingestion to AI model inference.
- High efficiency. The solution must make right design decisions at various levels to ensure efficient data processing, sufficiently utilizing today’s hardware and cloud architecture.
- Excellent developer experience. The solution must make it effortless for ad-hoc data exploration. Transition from insights to production should also be done with ease.
- Rich interoperability. The solution must embrace open standards and be ready to integrate with other systems whenever needed.
Why Sail?
Sail is the only solution we are aware of that is designed for the Big Data and AI unification. Besides the missions listed above, we enumerate a few more reasons that make Sail unique.
- Ease of migration from existing solutions. We work backward from the user’s needs. Smooth transition from existing tech stacks remains our top priority. We embrace existing APIs and SQL syntax, instead of defining our own interfaces.
- Scaling from your laptop to the cloud. The current Sail library is a lightweight single-process computation engine ready to be used on your laptop or in the cloud. The smooth user experience would stay the same, even when we implement distributed computing in the future.
- System-level performance. Written in Rust, Sail leverages the language’s performance and safety features for robust and efficient data processing. Sail is free from issues seen in JVM-based solutions, such as costly Python interoperability, null pointer exceptions, GC (garbage collection) pauses, and memory inefficiency.
Spark on Sail: A Dreamed-of Performance Boost
A computation framework with diverse use cases cannot be built in a single day. But we would like to make features accessible to users as soon as they are built. The current focus of Sail is to boost data analytics performance for PySpark users, and here we demonstrate how this has been achieved.
Benchmark Setup
We ran a derived TPC-H benchmark at a scaling factor of 100 (100 GB of raw data). The experiments were done in an AWS EC2 r8g.4xlarge instance (16 vCPU, 128 GB Memory). The raw data was converted to the Parquet format and stored in an EBS volume.
During earlier experiments, we found that Spark required additional disk space for spilling, so we prepared an additional EBS volume for temporary files. Both the data and temporary file EBS volumes were provisioned with 4,000 IOPS and the maximum allowed throughput of 1000 MB/s.
Credit: We conducted the experiments with the help of the DataFusion benchmark scripts.
Performance Comparison
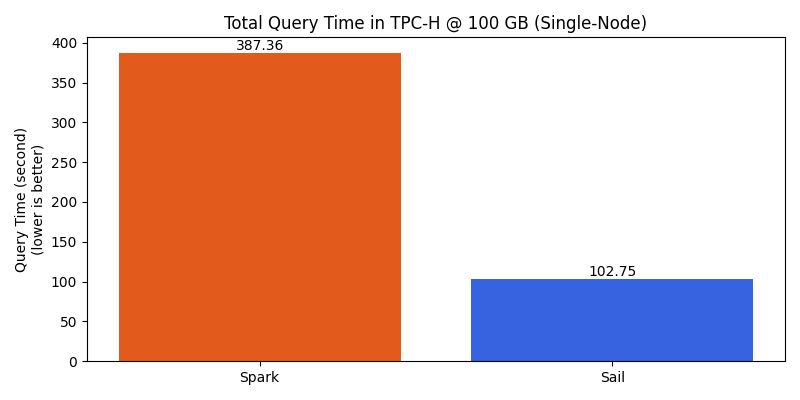
The figure below compares the overall performance between Sail and Spark. Sail completes the entire workload at nearly 4x in speed compared with Spark.
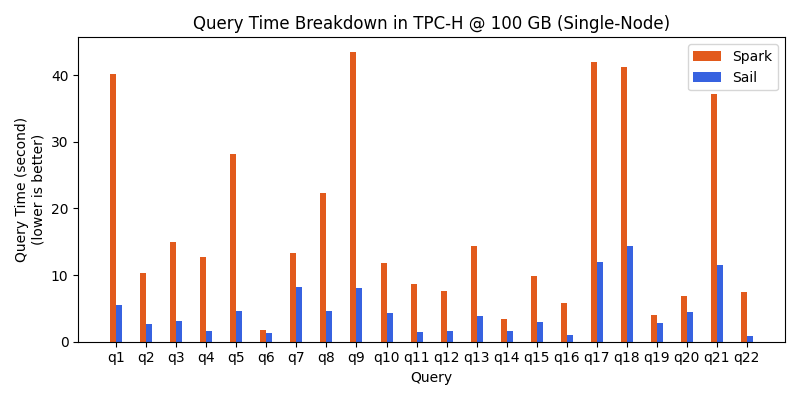
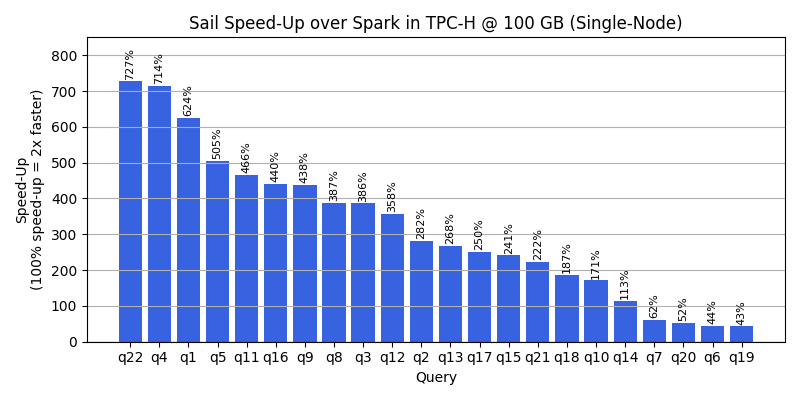
The following two figures show execution time comparison for individual queries, as well as sorted relative improvements. All queries benefit from a performance boost, with some experiencing over 700% speed-up.
Resource Utilization Comparison
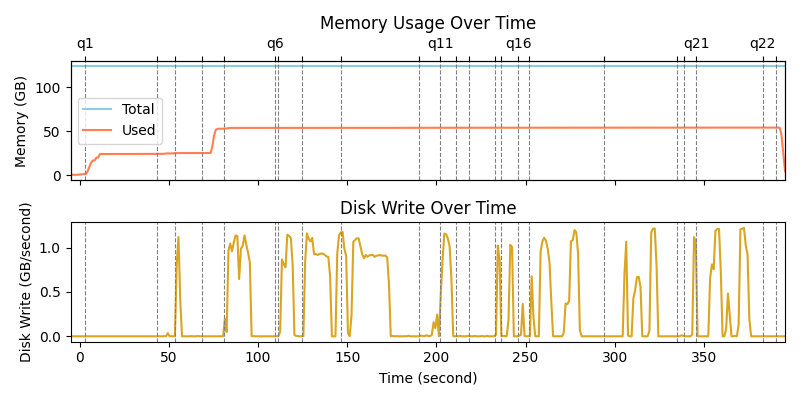
We analyze the memory and disk usage via AWS CloudWatch metrics with 1-second resolution.
The following figure shows that Spark consumed about 54 GB of memory during query execution, and spilled to disk for shuffle operations. Despite abundant available memory, Spark wrote over 110 GB of temporary data, peaking at over 46 GB in a rolling minute. This indicates inefficiencies in Spark’s resource management.
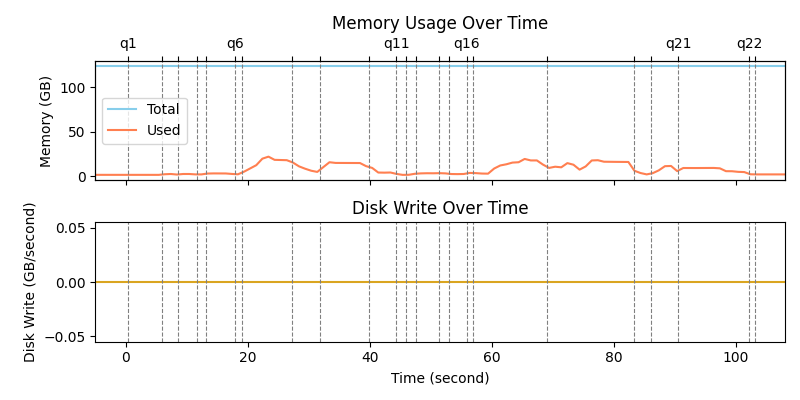
In contrast, the following figure shows drastically different resource consumption characteristics of Sail. At peak, Sail utilized approximately 22 GB of memory, but this usage lasted for only one second. Sail proactively released memory at the end of query execution and had zero disk usage, relying solely on the available memory for efficient computation.
Key Findings
Compared with Spark, Sail’s efficiency translates to significant cost reductions. Sail runs the same computation in 1/4 of the time, with a potential to run comfortably on 1/4 of the instance size (i.e., r8g.xlarge with 32 GB memory) due to small resource consumption. Combining these factors, and without even considering the cost saving due to zero disk usage, Sail could run the same workload at 1/16 (94% reduction) of the cost and a nearly 4x speed-up.
The results suggest high efficiency of Sail. It can handle larger datasets on the same hardware, or achieve similar performance on less powerful and less expensive infrastructure.
Getting Started
Sail is now available at https://github.com/lakehq/sail. We will publish the first packaged release in the coming weeks. Visit LakeSail.com to stay updated on our latest developments, or contact us at hello@lakesail.com for any inquiries.
We are excited to bring this innovation to the wider data and AI community, and we are eager to hear your feedback. Join us in shaping the future of Big Data and AI!